
Diffusion modeling in semantic space Semantic spaces include the latent spaces of pretrained vision encoders like SigLIP 2, Web-DINO, and V-JEPA 2.1, these encoders are trained to optimize for semantic similarity and can include language alignment. preserves policy-relevant structures better than reconstruction Reconstruction spaces include VAE-style spaces like SD3 VAE, Cosmos and VA-VAE that are primarily trained for pixel reconstruction. However some might include additional training objectives. spaces.
Video diffusion world models offer a practical way to test and improve robot control policies. As these models increasingly rely on latent diffusion, choosing the right latent space is critical. While the standard approach uses VAEs trained purely for pixel reconstruction, semantic spaces from pretrained encoders offer a powerful alternative. We systematically evaluate six reconstruction and semantic encoders for action-conditioned LDMs. By assessing them across three axes: visual fidelity, planning/policy performance, and latent quality, we show:
- Visuals aren't everything: Reconstruction space (VAEs, Cosmos) models achieve strong pixel scores at larger model sizes, but still lag behind on many policy-relevant metrics and scale worse with multiple camera views.
- Semantics lead on policy-facing metrics: Semantic space (V-JEPA 2.1, Web-DINO, SigLIP 2) models generally excel at planning, latent quality, and downstream VLA policy evals. Their generated rollouts also stay closer to the encoder-decoder ceiling for visual fidelity.
We establish semantic latent spaces as a stronger foundation for policy-relevant robotic diffusion world models.
Why Semantic Latent Spaces?
While reconstruction-aligned latents are the standard in latent diffusion world modeling due to their visual generation quality, recent work suggests that pretrained representation spaces can improve semantic consistency and generalization in image generation and text-to-image generation.
For robotic world models, the representation must also preserve how actions change object state, scene geometry, and task progress.
Thus we ask, do semantic latents offer similar advantages for robotic world modeling?
To isolate the effect of representation, we fix the transition model backbone, dataset, and action conditioning, varying only the encoder-defined latent interface.
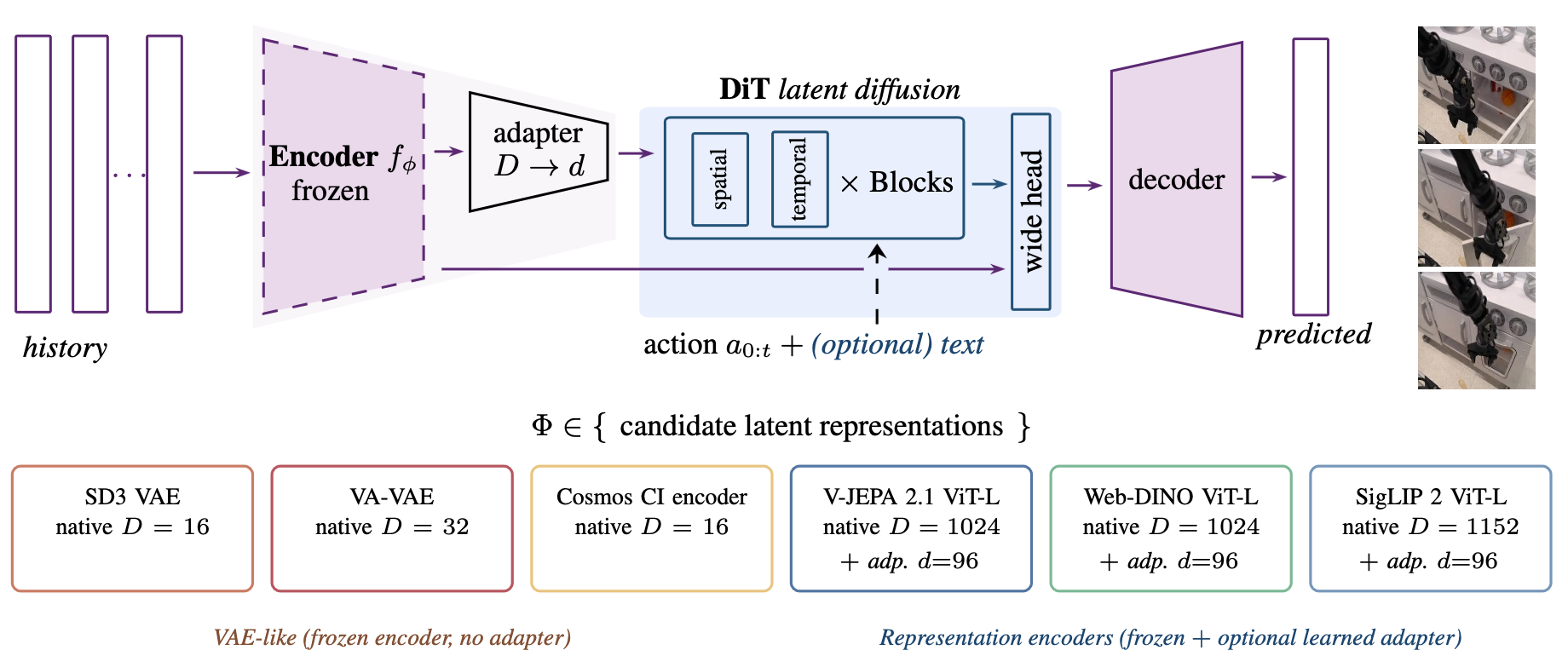
We train world model variants using reconstruction-aligned encoders (SD3 VAE, VA-VAE, Cosmos) versus semantics-aligned encoders (V-JEPA 2.1, Web-DINO, SigLIP 2) to evaluate their effect on action-faithful dynamics.
Semantic Spaces Outperform Reconstruction Spaces
Our study varies only the representation space used by the latent transition model. Each encoder is evaluated along three axes: latent representation qualityTests whether generated latents preserve action information and task-success information after rollout generation., pixel fidelity, and planningUses CEM to search for action sequences whose predicted latent rollout best reaches a target state. and downstream VLA policy performanceRuns a vision-language-action policy inside the generated world model and judges whether the task succeeds.. The central pattern is not a simple tradeoff where semantic spaces sacrifice visual quality for policy: at DiT-S, semantic variants are visually competitive and often stronger on content and motion metrics, while also unlocking better action recovery, CEM planningCross-entropy method planning searches over candidate action sequences and selects actions whose predicted future latents match the target transition., task-success probes, and OOD robustnessMeasures whether performance holds under distribution shifts such as distractor objects or changed instructions.. At larger DiT scale, reconstruction latents recover several visual wins, but semantic spaces retain stronger latent-space and policy-facing benefits.
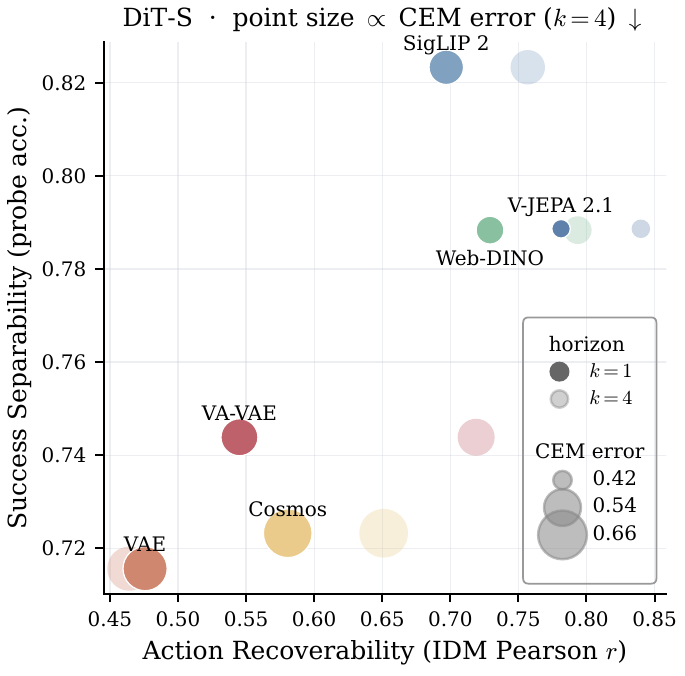
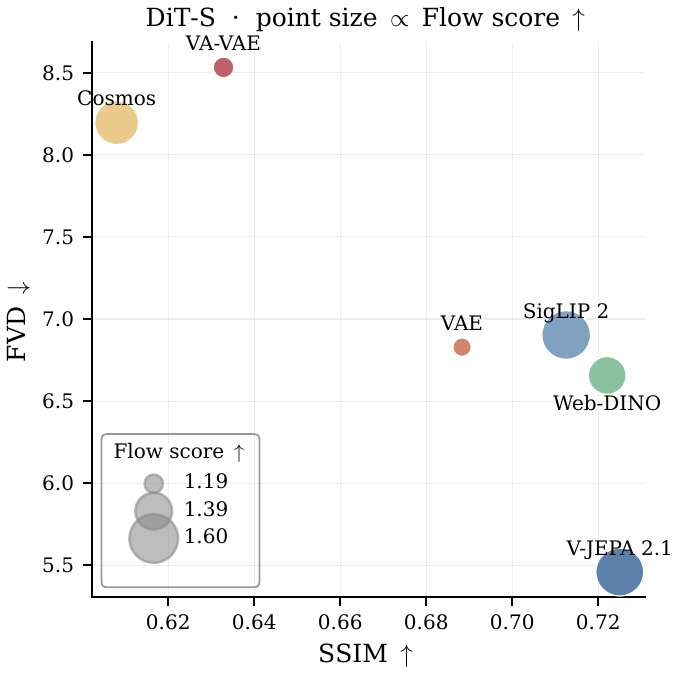
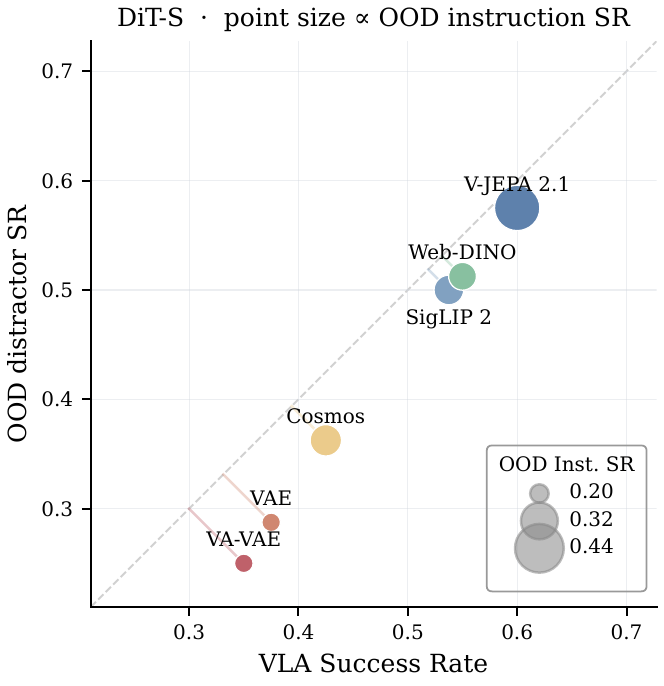
Across DiT-S models, semantic encoders move the frontier on action recoverability, episode success classification accuracy, planning error, VLA success, robustness, and many visual/content/motion metrics.
Takeaway: A robotic world model latent space should preserve controllable, task-relevant state changes while staying visually decodable. Semantic latents are competitive on visual fidelity and generally stronger on action, planning, robustness, and policy-facing metrics; reconstruction-aligned latents recover more visual advantages at larger model sizes.
Action and Task Semantics Survive Better in Representation Space
The transition model operates in latent space, so we directly probe generated latents. Inverse-dynamics models (IDM)Given latent state changes, an IDM tests whether we can recover the robot action that caused them. recover action chunks more reliably from semantic latents, and task-success classification probesThese probes test whether a generated latent rollout still contains enough instruction-conditioned information to classify whether the task succeeded. retain more instruction-conditioned outcome information after rollout generation.
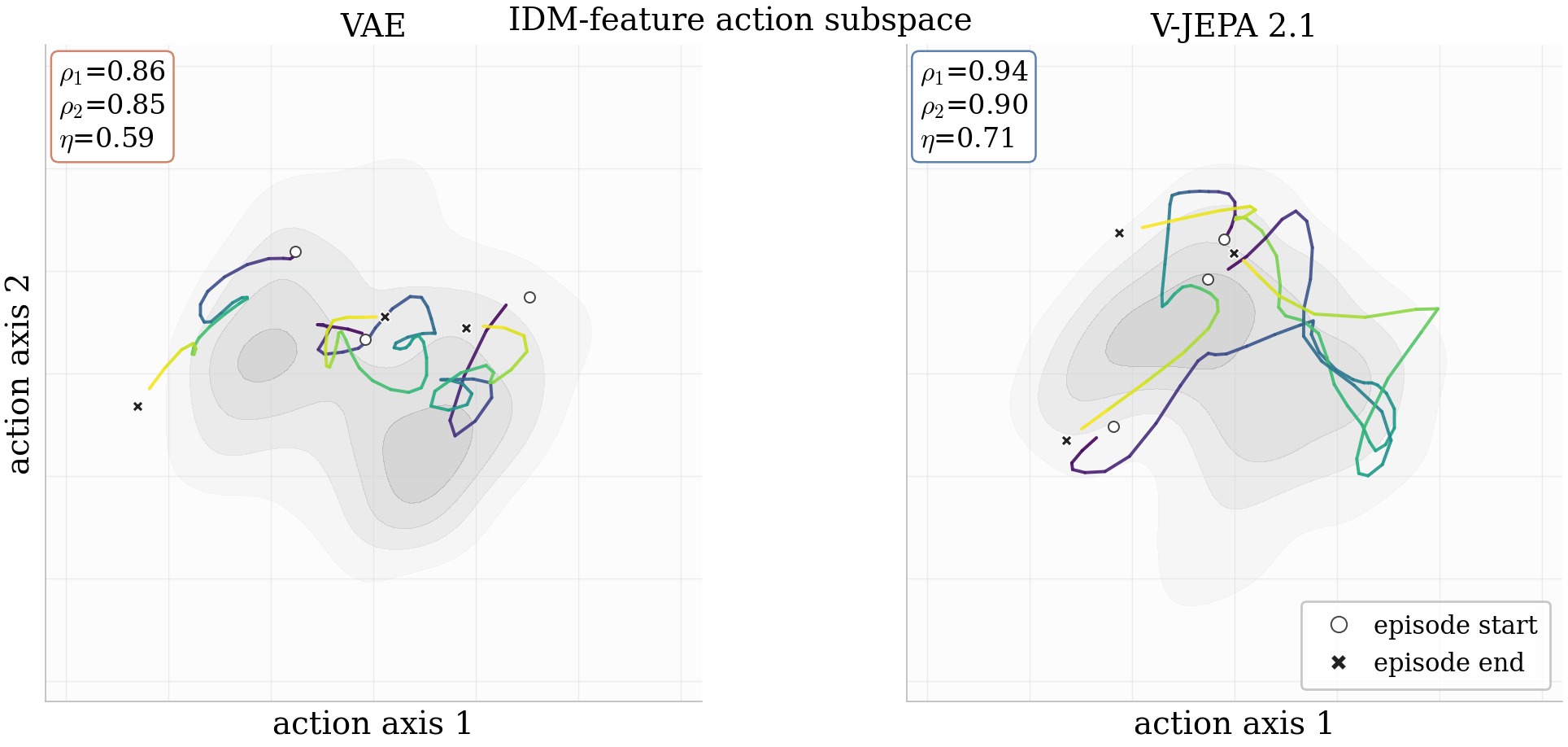
Action trajectories induced by encoder spaces: episode rollouts projected onto the top-2 canonical-correlation directions between IDM features and ground-truth actions. Semantic spaces like V-JEPA 2.1 show stronger action recoverability than reconstruction-aligned spaces, and this advantage largely persists after world-model generation.
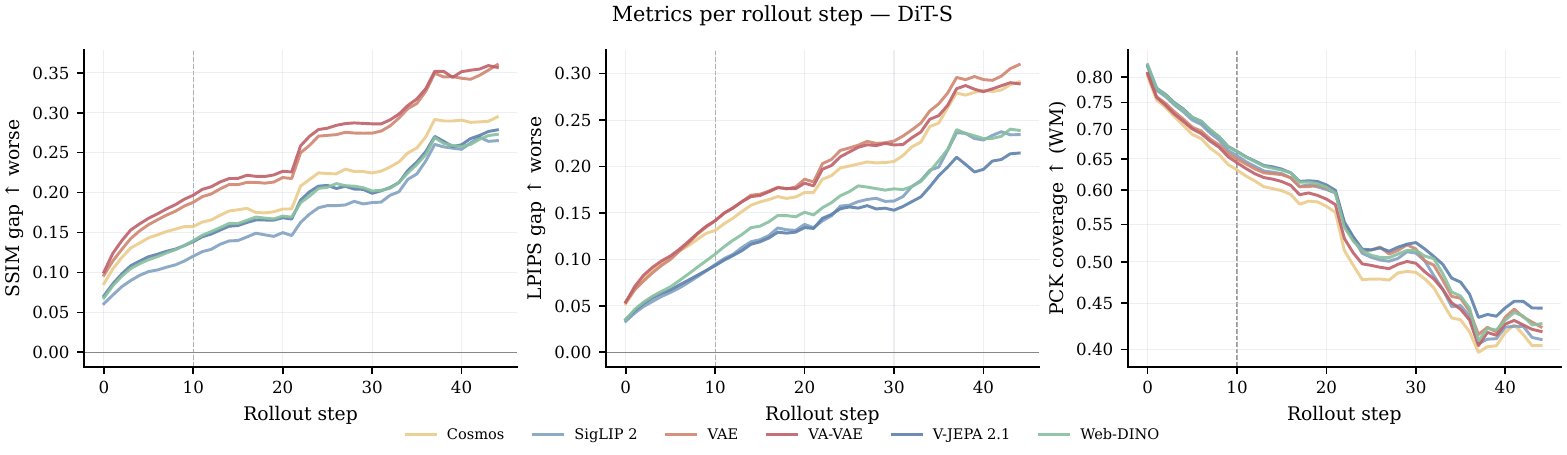
Over long autoregressive rollouts, semantic latent spaces remain competitive beyond the training horizon. They also often have a lower gap between the encoder-decoder ceilingThe best visual quality achievable when the decoder receives true encoder latents instead of generated world-model latents. and world model generated pixels.
Adapters and Scaling with Camera Views
We show that learning a compact VAE-like adapterAdapter compression maps high-dimensional semantic features into smaller KL-regularized latents, making diffusion and decoding easier. for semantic encoders can make diffusion modeling easier, leading to higher visual fidelity and better policy performance at the same model size, while losing on fine-grained latent-space planning. We also study multi-viewTraining with multiple camera views of the same robot episode, which can expose more geometry and action information. finetuning: it improves action recovery but can degrade video quality under limited multi-view data, with semantic encoders losing less visual fidelity than reconstruction-aligned spaces.
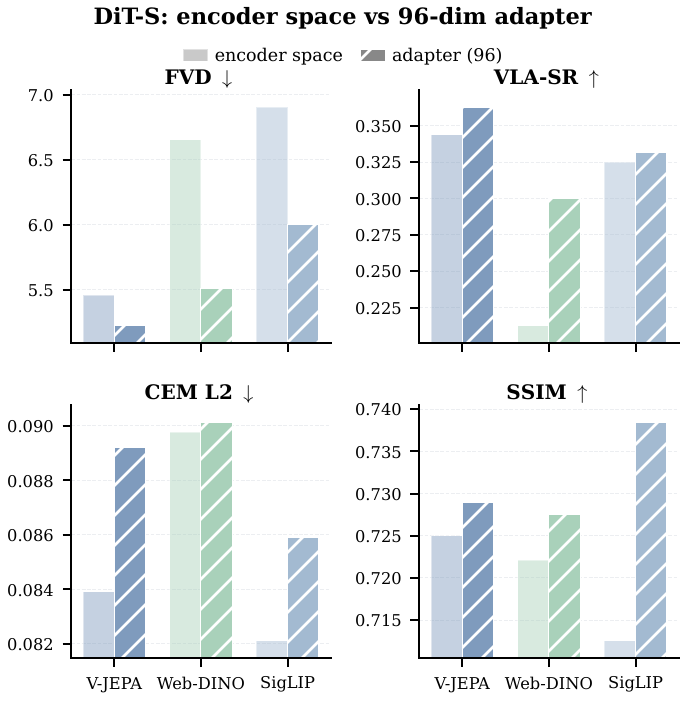
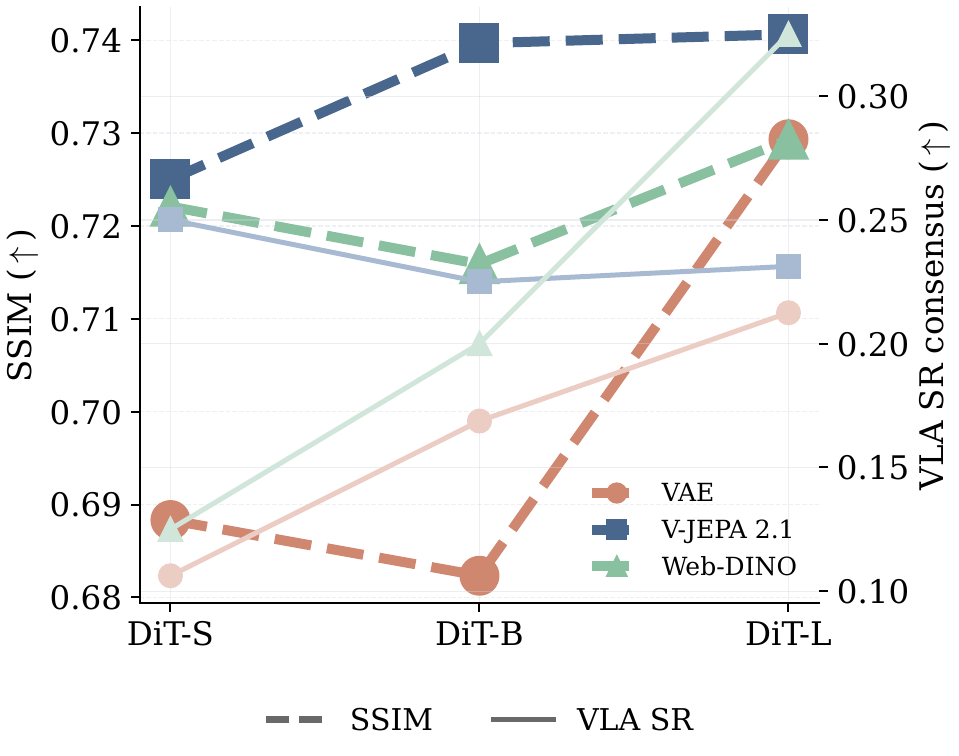
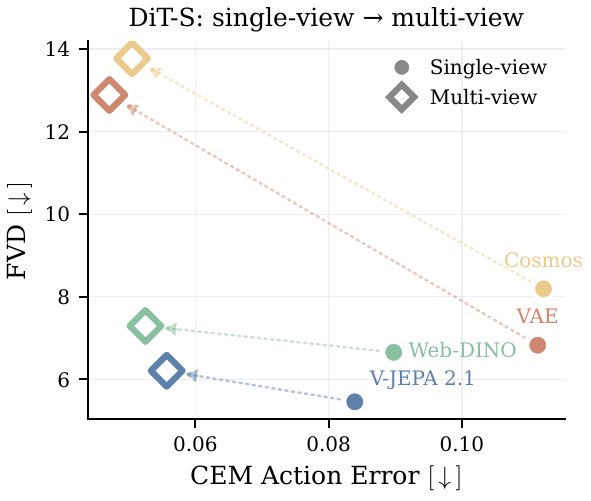
Adapter dimension, transition-model scale, and multi-view training each affect the visual-policy tradeoff.
A Practical Recipe for Semantic-Space Diffusion World Models
A practical default is to start with a strong frozen semantic encoder, keep the comparison controlled with a fixed action-conditioned DiTA diffusion transformer transition model that predicts future latent trajectories conditioned on observation history and robot actions. backbone, and evaluate with policy-facing metrics rather than visual fidelity alone. High-dimensional semantic spaces can be difficult for diffusion, so we make them more diffusion-friendly with a dimension-dependent noise-schedule shift, an optional S-VAE adapter when compact decoded rollouts matter, and a lightweight wide DDT head for native semantic features. The adapter improves diffusion and decoding, but native semantic features can preserve finer action geometry for planning.
Recipe: start with a strong semantic encoder, add compact adapter latents when decoding and efficiency matter, and evaluate with policy-facing metrics instead of choosing only by pixel fidelity.
Interactive Rollout Examples
The rollouts below (using DiT-L) illustrate how different latent spaces behave under the same ground-truth actions, multi-view inputs, VLA policy attempts, and OOD distractor settings. Check marks and crosses indicate VLM-judged task success or failure; these examples illustrate the aggregate trends.
Rollouts with ground truth actions
These single-view rollouts mostly show generation and reconstruction performance under ground-truth actions. Compare each world-model video to the ground-truth video and look for hallucinated objects, incorrect object interactions, or missed contact dynamics; semantic world models generally preserve object interactions better.
Multi-View rollouts
These examples show the same setup with three camera views of the scene. Compare the generated views against ground truth and look for whether object motion, contact, and hallucinations remain consistent across viewpoints.
VLA Policy attempts
These rollouts show VLA policy attempts conditioned on the task instruction. The check mark or cross is the VLM success rating; compare models for hallucinations, visual degradation, missed interactions, and whether the policy behavior still follows the instruction.
VLA Policy with OOD objects
Compare the top row, which starts from the initial clean frame, with the bottom row, where an image editing model has inserted OOD distractor objects into the initial frame. Look for hallucinations, VLA policy misbehavior, and whether the rollout remains faithful to the task despite the distractors; semantic spaces are usually more robust.
Citation
@article{nilaksh2026reconstruction,
title={Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models},
author={Nilaksh and Saurav Jha and Artem Zholus and Sarath Chandar},
year={2026},
eprint={2605.06388},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2605.06388},
}